Wally J
2023-12-06 17:13:27 UTC
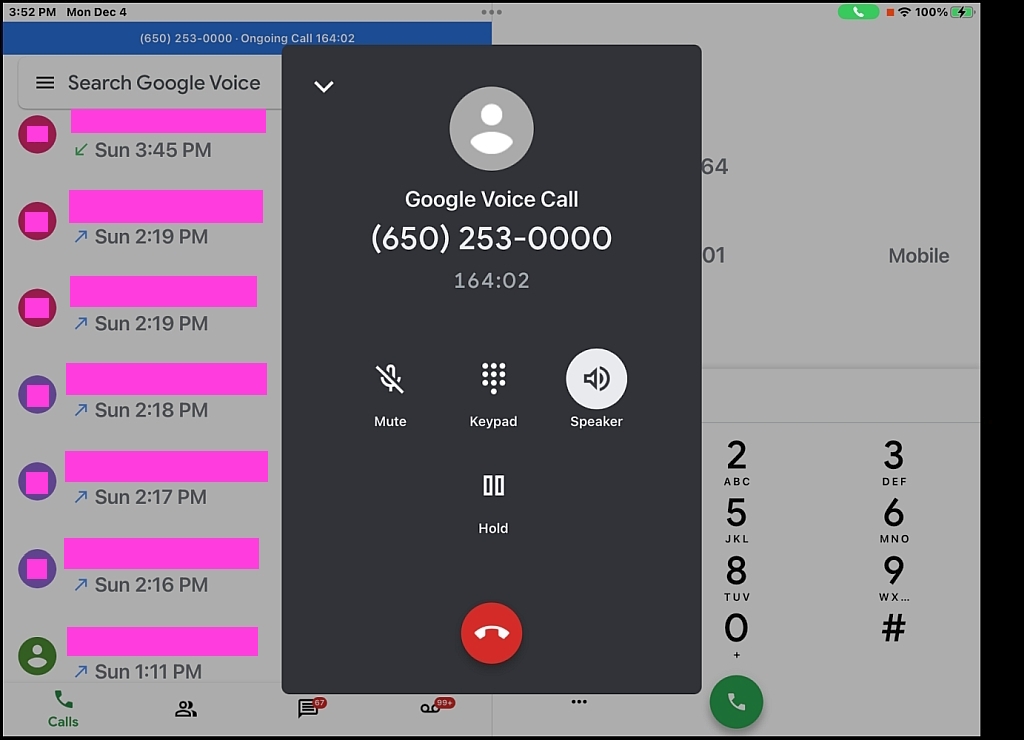
Given a call to Mountainview is never picked up by a human being...
<Loading Image... > +1 (650) 253-0000
> +1 (650) 253-0000
If you care about either Usenet or the DejaNews DejaGoogle search
engine (which provides links to specific Usenet posts), then...
*Please Do This!*
<https://groups.google.com/g/google-usenet/about>
Which will look like this:
<Loading Image...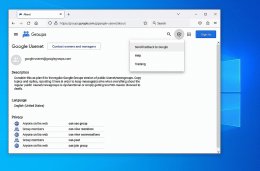 >
>
The DejaGoogle search engine is useful to everyone (not just us) because:
a. DejaGoogle doesn't require an account or paying for retention
b. DejaGoogle links work for everyone (even your 99 year old mother)
c. DejaGoogle only needs a web browser (which everyone has)
The problem with all this spam from Google servers is that even finding the
URI to an article posted _today_ is a mess of wading through that garbage.
<Loading Image... >
>
Details follow...
That is the easiest way (I know of) to complain to Google about
their Google-Groups servers allowing Google Usenet portal spam
(which ruins their own Usenet DejaGoogle search engine output)
<https://groups.google.com/g/comp.mobile.android>
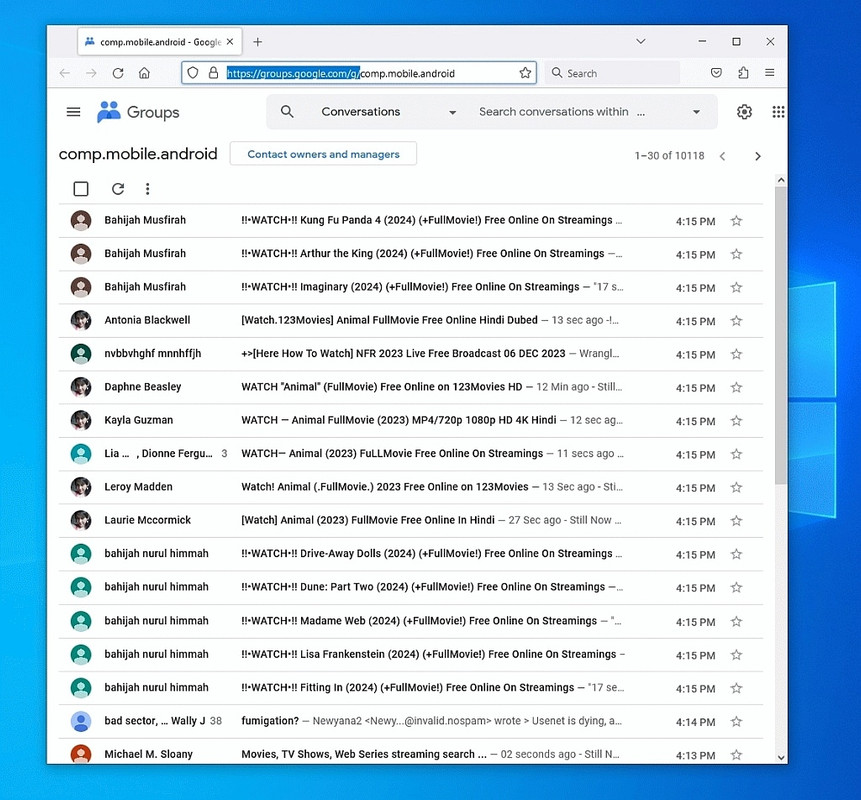
You're welcome to upload this screenshot showing the problem:
<Loading Image...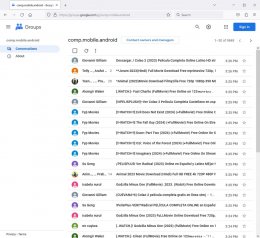 >
>
Together, maybe we can get Google to at least look at the problem we face.
*Please do this today:*
1. Go to <https://groups.google.com/g/google-usenet/about>
2. Click the "Gear" icon at the top right of that web page
3. Select the option to "Send feedback to Google"
Box 1: "Tell us what prompted this feedback."
Box 2: "A screenshot will help us better understand your feedback."
Optionally, you can do the deluxe version of sending feedback to Google.
A. In tab 1, go to <https://groups.google.com/g/comp.mobile.android>
B. Take a screenshot & save it to a date-related name you can easily find.
C. In tab 2, go to <https://groups.google.com/g/google-usenet/about>
D. Click the "Gear" icon at the top right of that "about" web page
E. In the first box "Tell us what prompted this feedback."
tell Google the problem in a way that Google 'may' care about.
For example, tell them something like "Your Google Groups servers
are allowing obvious off-topic rampant spamming by few individuals
<https://groups.google.com>
such that your own Google Groups Server Search Engine
<http://groups.google.com/g/comp.mobile.android>
is now useless because a few users are abusing your Google servers."
F. In the second box upload that screenshot of the first tab.
G. Press the "Send" button on the bottom right of that second tab.
Here's what it looks like, with every step above documented below.
<Loading Image...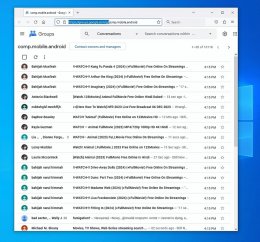 >
>
<Loading Image... >
>
<Loading Image... >
>
<Loading Image... >
>
<Loading Image... >
>
<Loading Image...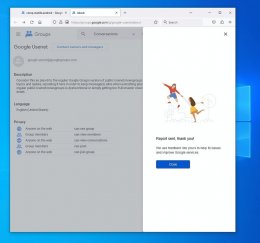 >
>
In summary, I tried contacting Google to find a better way, to no avail.
<Loading Image... >
>
So this online complaint form is the only one that I know about.
<https://groups.google.com/g/google-usenet/about>
If you know of a better way to complain about this, please let us know.
<Loading Image...
 > +1 (650) 253-0000
> +1 (650) 253-0000If you care about either Usenet or the DejaNews DejaGoogle search
engine (which provides links to specific Usenet posts), then...
*Please Do This!*
<https://groups.google.com/g/google-usenet/about>
Which will look like this:
<Loading Image...
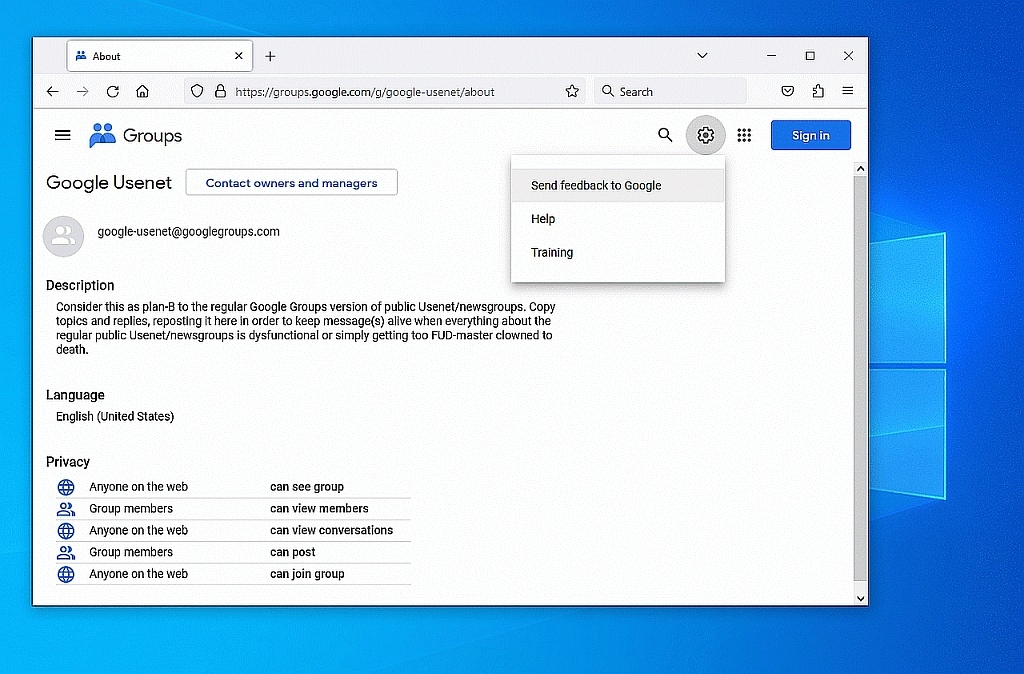 >
>The DejaGoogle search engine is useful to everyone (not just us) because:
a. DejaGoogle doesn't require an account or paying for retention
b. DejaGoogle links work for everyone (even your 99 year old mother)
c. DejaGoogle only needs a web browser (which everyone has)
The problem with all this spam from Google servers is that even finding the
URI to an article posted _today_ is a mess of wading through that garbage.
<Loading Image...
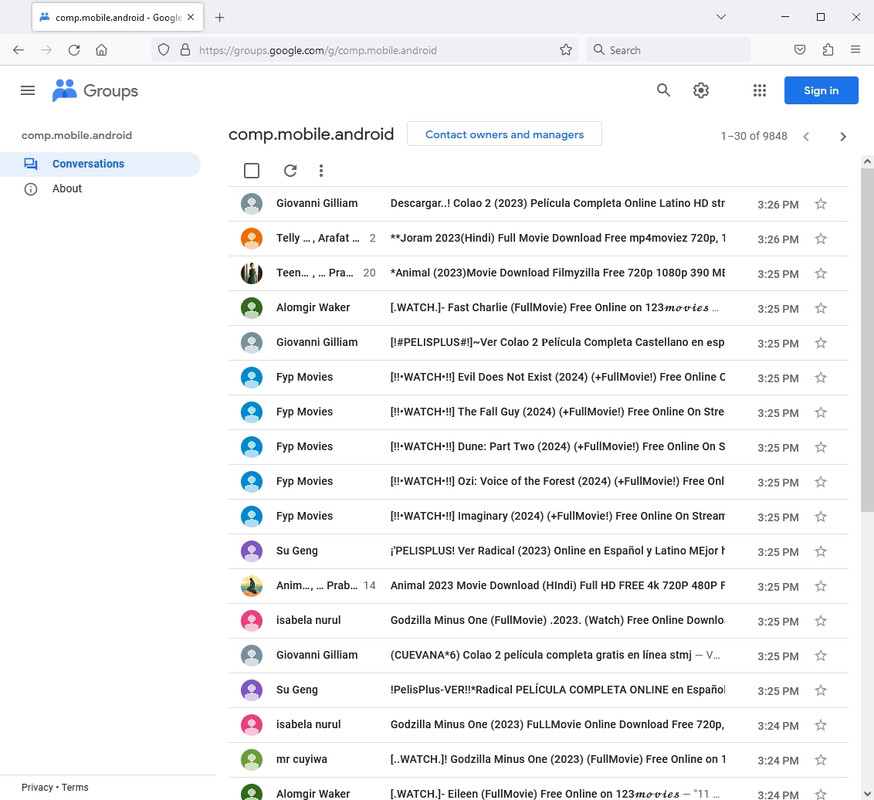 >
>Details follow...
That is the easiest way (I know of) to complain to Google about
their Google-Groups servers allowing Google Usenet portal spam
(which ruins their own Usenet DejaGoogle search engine output)
<https://groups.google.com/g/comp.mobile.android>
You're welcome to upload this screenshot showing the problem:
<Loading Image...
 >
>Together, maybe we can get Google to at least look at the problem we face.
*Please do this today:*
1. Go to <https://groups.google.com/g/google-usenet/about>
2. Click the "Gear" icon at the top right of that web page
3. Select the option to "Send feedback to Google"
Box 1: "Tell us what prompted this feedback."
Box 2: "A screenshot will help us better understand your feedback."
Optionally, you can do the deluxe version of sending feedback to Google.
A. In tab 1, go to <https://groups.google.com/g/comp.mobile.android>
B. Take a screenshot & save it to a date-related name you can easily find.
C. In tab 2, go to <https://groups.google.com/g/google-usenet/about>
D. Click the "Gear" icon at the top right of that "about" web page
E. In the first box "Tell us what prompted this feedback."
tell Google the problem in a way that Google 'may' care about.
For example, tell them something like "Your Google Groups servers
are allowing obvious off-topic rampant spamming by few individuals
<https://groups.google.com>
such that your own Google Groups Server Search Engine
<http://groups.google.com/g/comp.mobile.android>
is now useless because a few users are abusing your Google servers."
F. In the second box upload that screenshot of the first tab.
G. Press the "Send" button on the bottom right of that second tab.
Here's what it looks like, with every step above documented below.
<Loading Image...
 >
><Loading Image...
 >
><Loading Image...
 >
><Loading Image...
 >
><Loading Image...
 >
><Loading Image...
 >
>In summary, I tried contacting Google to find a better way, to no avail.
<Loading Image...
 >
>So this online complaint form is the only one that I know about.
<https://groups.google.com/g/google-usenet/about>
If you know of a better way to complain about this, please let us know.
--
Together we can get Google to stop spamming their own Usenet search engine.
Together we can get Google to stop spamming their own Usenet search engine.